
Working Paper
Abstract
Conventional approaches to estimating latent preferences face numerous constraints. They are limited not only by the dearth of data from which preferences can be learned, usually roll-call votes, but also by the assumptions and limitations built into the statistical models they use to estimate these preferences. Commonly employed models such as DW-Nominate from the legislative studies literature or Bailey, Strezhnev, and Voeten’s (2017) dynamic IRT from IR are no exception. Both are limited to roll-call votes and require a priori assumptions about the number of latent dimensions that must be validated a posteriori.
I develop a flexible, non-parametric model that allows researchers to combine multi-modal data, such as speeches and votes, and extract ideal points along as many dimensions as are stably present. I validate the model by examining it’s performance on the UNGA voting dating, using Bailey and company’s ideal points as a baseline, and find evidence for upwards of three dimension. I also apply the model to combined UNGA votes and debates as well as UNGA votes and Universal Period Review statements, illustrating the model’s utility for estimating topic-specific preferences that are still anchored to well-established latent constructs.
Results
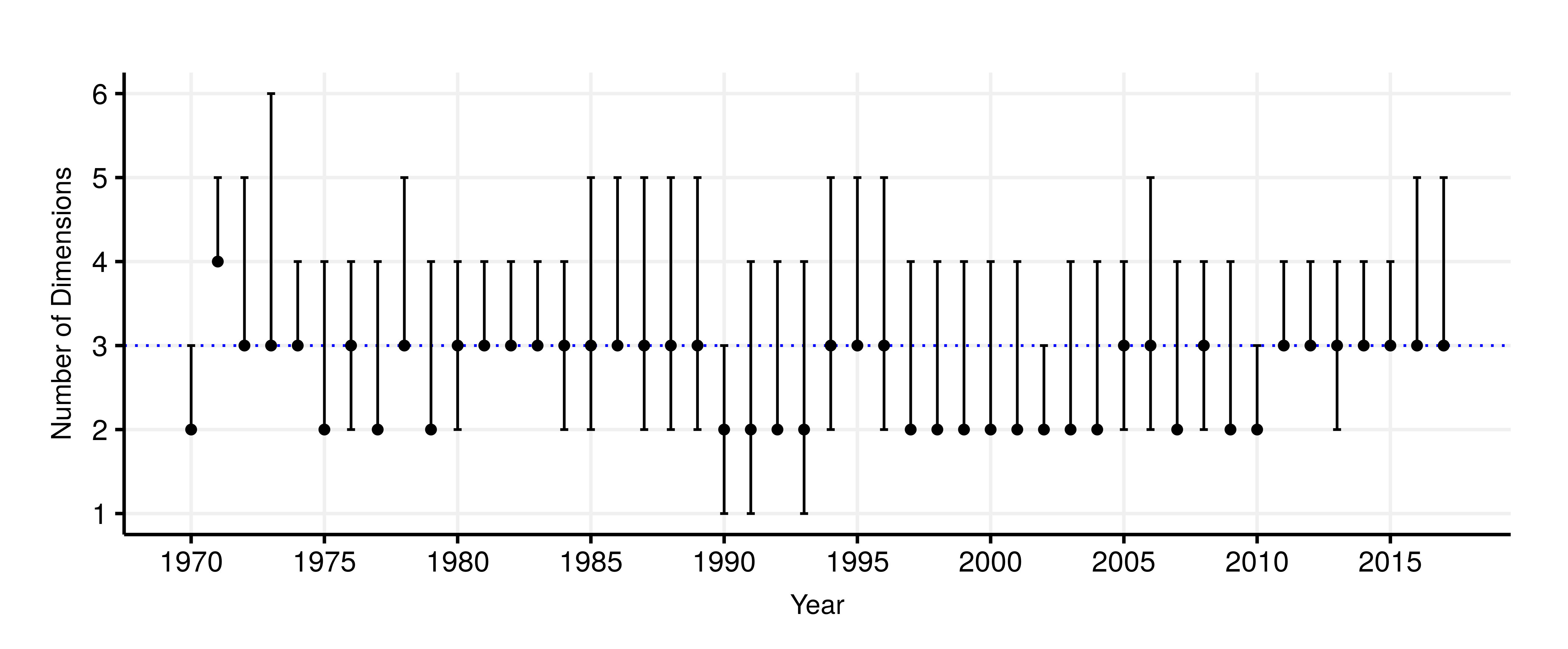
Dimensionality of the 25th-72nd UN General Assembly. Points indicate the median posterior number of dimensions mmBPFA found after burn-in. Bars represent 95% HPD intervals. The median number of dimensions across sessions is 3, indicated by the blue dotted-line.
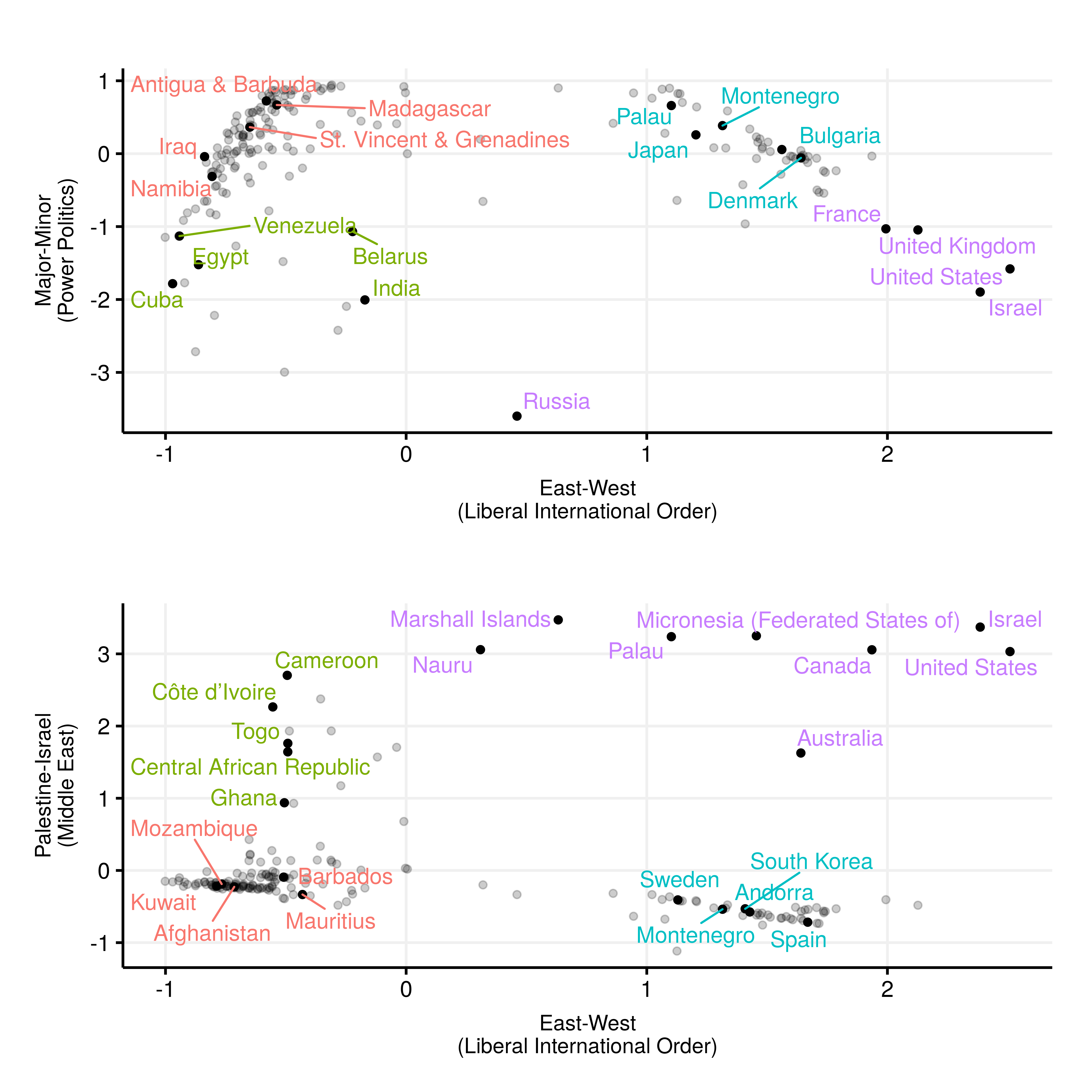
Ideal Point-Dimension Scatter Plots for 70th Session of UNGA (2015–2016). (top) Dimension 1 (x-axis) versus Dimension 2 (y-axis). (bottom) Dimension 1 (x-axis) versus Dimension 3 (y-axis).

